









《三体》中的歌者或真实存在
来源:探索宇宙奥秘
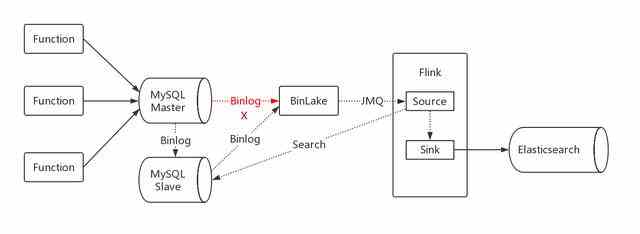
【编者按】订购数据的数据异构有些不同,订购数据分为主表和扩展表,在 MySQL 中两张表的数据需要整合异构成一条记录存储到 Es 中。如果采用并行消费,则会出现 Flink 接收消息先后问题,简单说,就是有可能先接收到扩展表的 binlog 后接收到主表的 binlog。
所以改造的方案是,只订阅主表的 binlog,接收到消息后,通过反查 MySQL 的方式,进行数据整合,然后进行数据异构。考虑到对 MySQL 的压力,不能反查 Master MySQL,需要订阅 Slave MySQL。所以,这个方案的缺点是,不仅增加了 IO 的交互,而且数据异构的延迟较大。
商品数据异构
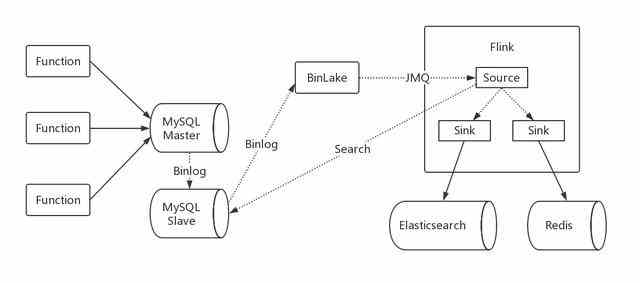
而商品数据异构是使用并发消费的,因为商品数据不需要保证严格的顺序,所以,商品数据异构的方式采用和订购数据同样的模式,由于商品数据需要缓存,所以,不仅要 Elasticsearch,还要写 redis,这样的架构设计使用 Flink 也很简单。
总结
Flink 被越来越多业务所使用,作为高性能的分布式流处理平台,不断的改进我们所使用的技术,以及不断突破我们原有的固化思维。其实,最早的设计方案是在系统里接收 Binlog 消息,然后处理,再异构存储写入 Elasticsearch。而采用 Flink,逐步理解流处理模式,我认为更在于思想理念上的改变。
希望本文大家有所帮助。
来源:探索宇宙奥秘
来源:千龙网
来源:3DMGAME
来源:小雷讲历史
来源:扬州日报
来源:小雷讲历史
来源:数码评价Z
来源:北京时间
来源:云自媒科技
来源:移动互联网新媒体
来源:科技研读
来源:智电网
来源:商业经济观察
来源:探索宇宙奥秘
来源:cnBeta
条评论